XCiT: Cross-Covariance Image Transformers (Facebook AI Machine Learning Research Paper Explained)
#xcit #transformer #attentionmechanism
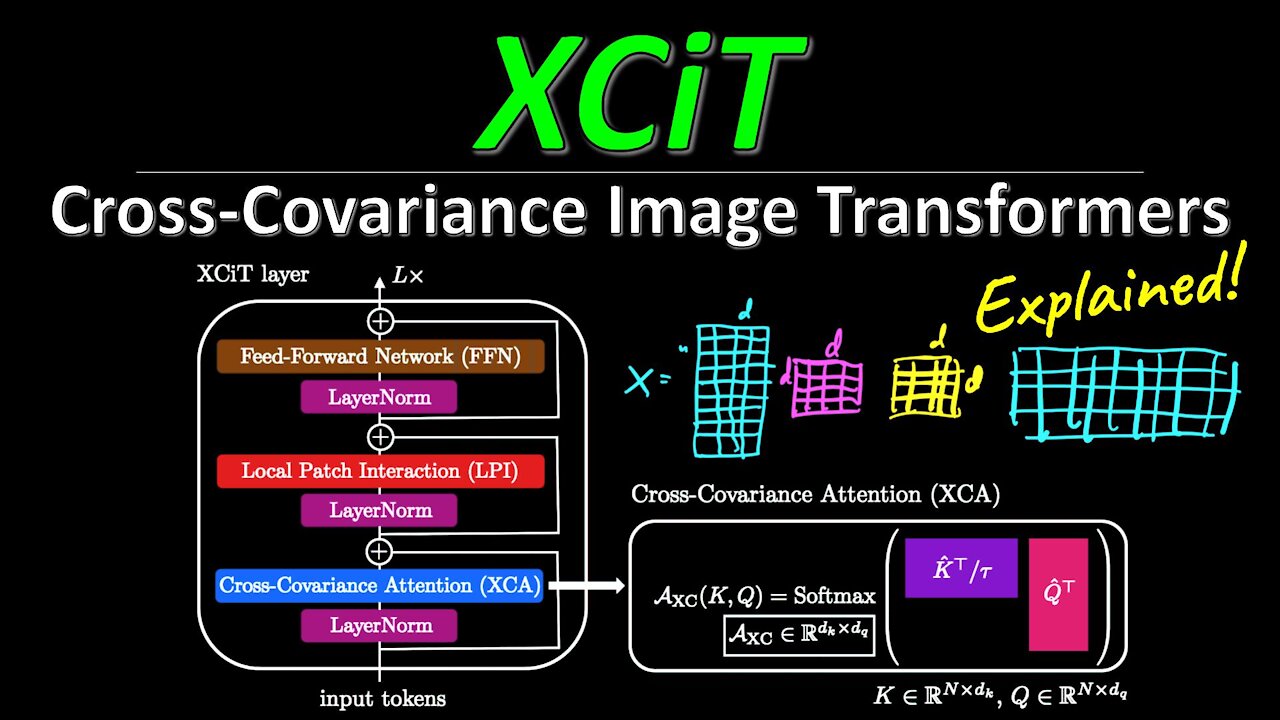
After dominating Natural Language Processing, Transformers have taken over Computer Vision recently with the advent of Vision Transformers. However, the attention mechanism's quadratic complexity in the number of tokens means that Transformers do not scale well to high-resolution images. XCiT is a new Transformer architecture, containing XCA, a transposed version of attention, reducing the complexity from quadratic to linear, and at least on image data, it appears to perform on par with other models. What does this mean for the field? Is this even a transformer? What really matters in deep learning?
OUTLINE:
0:00 - Intro & Overview
3:45 - Self-Attention vs Cross-Covariance Attention (XCA)
19:55 - Cross-Covariance Image Transformer (XCiT) Architecture
26:00 - Theoretical & Engineering considerations
30:40 - Experimental Results
33:20 - Comments & Conclusion
Paper: https://arxiv.org/abs/2106.09681
Code: https://github.com/facebookresearch/xcit
Abstract:
Following their success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens ,i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a "transposed" version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k.
Authors: Alaaeldin El-Nouby, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, Hervé Jegou
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/yannic-ki...
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
-
 6:38
6:38
Datakademy
3 years agoAutomated Machine Learning Using TPOT
76 -
 5:58
5:58
Datakademy
3 years agoAutomated Machine Learning Using Auto-Sklearn (Scikit-learn)
271 -
 3:58
3:58
Blackstone Griddles
23 hours agoLeftover Turkey with White Country Gravy
12.5K1 -
 42:19
42:19
Lights, Camera, Barstool
9 hours agoDoes 'Glicked' Meet The Hype? 'Gladiator II' And 'Wicked' Reviews
11.9K2 -
 LIVE
LIVE
MTNTOUGH Fitness Lab
2 hours agoRandy Newberg's Shot of a Lifetime: The Intense 5-Second Window for a Trophy Ram | MTNT POD #91
135 watching -

World Nomac
9 hours agoThe side of Las Vegas they don't want you to know about
3.25K -
 1:56:32
1:56:32
TheSaf3Hav3n
3 hours ago| CALL OF DUTY: BLACK OPS 6 - NUKETOWN | GET IN HERE!! | #RumbleTakeOver |
9.65K -
 LIVE
LIVE
MissesMaam
6 hours agoMY FAVORITE ARTIST IS FINALLY IN FORTNITE 💚✨
114 watching -
 2:02:34
2:02:34
The Quartering
4 hours agoTrump Tariffs Immediately Work, Thanksgiving Cost Insanity, Hollywood Actor In Psych Ward From Trump
75.3K26 -
 36:54
36:54
Stephen Gardner
3 hours ago🔥I can't believe what Happened To Trump's insider pick!
16.9K33