FNet: Mixing Tokens with Fourier Transforms (Machine Learning Research Paper Explained)
#fnet #attention #fourier
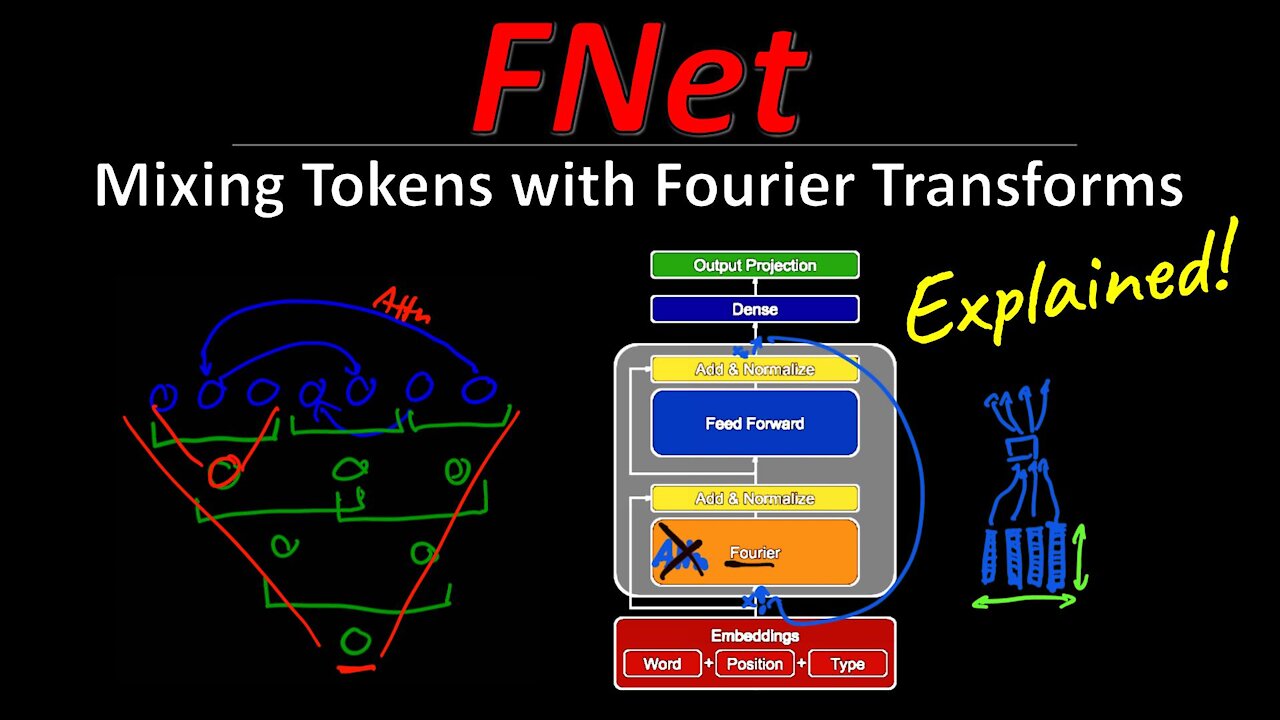
Do we even need Attention? FNets completely drop the Attention mechanism in favor of a simple Fourier transform. They perform almost as well as Transformers, while drastically reducing parameter count, as well as compute and memory requirements. This highlights that a good token mixing heuristic could be as valuable as a learned attention matrix.
OUTLINE:
0:00 - Intro & Overview
0:45 - Giving up on Attention
5:00 - FNet Architecture
9:00 - Going deeper into the Fourier Transform
11:20 - The Importance of Mixing
22:20 - Experimental Results
33:00 - Conclusions & Comments
Paper: https://arxiv.org/abs/2105.03824
ADDENDUM:
Of course, I completely forgot to discuss the connection between Fourier transforms and Convolutions, and that this might be interpreted as convolutions with very large kernels.
Abstract:
We show that Transformer encoder architectures can be massively sped up, with limited accuracy costs, by replacing the self-attention sublayers with simple linear transformations that "mix" input tokens. These linear transformations, along with simple nonlinearities in feed-forward layers, are sufficient to model semantic relationships in several text classification tasks. Perhaps most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder with a standard, unparameterized Fourier Transform achieves 92% of the accuracy of BERT on the GLUE benchmark, but pre-trains and runs up to seven times faster on GPUs and twice as fast on TPUs. The resulting model, which we name FNet, scales very efficiently to long inputs, matching the accuracy of the most accurate "efficient" Transformers on the Long Range Arena benchmark, but training and running faster across all sequence lengths on GPUs and relatively shorter sequence lengths on TPUs. Finally, FNet has a light memory footprint and is particularly efficient at smaller model sizes: for a fixed speed and accuracy budget, small FNet models outperform Transformer counterparts.
Authors: James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/yannic-ki...
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
-

Alex Zedra
4 hours agoLIVE! Trying to get achievements in Devour
78K7 -
 2:00:43
2:00:43
The Quartering
7 hours agoThe MAGA Wars Have Begun! Vivek & Elon Get Massive Backlash & Much More
81.1K24 -
 1:25:53
1:25:53
Kim Iversen
3 days agoStriking Back: Taking on the ADL’s Anti-Free Speech Agenda
67.8K25 -
 49:35
49:35
Donald Trump Jr.
10 hours agoA New Golden Age: Countdown to Inauguration Day | TRIGGERED Ep.202
141K169 -
 1:14:34
1:14:34
Michael Franzese
9 hours agoWhat's Behind Biden's Shocking Death Row Pardons?
61.4K42 -
 9:49
9:49
Tundra Tactical
8 hours ago $13.14 earnedThe Best Tundra Clips from 2024 Part 1.
76.9K7 -
 1:05:19
1:05:19
Sarah Westall
8 hours agoDying to Be Thin: Ozempic & Obesity, Shedding Massive Weight Safely Using GLP-1 Receptors, Dr. Kazer
70.5K19 -
 54:38
54:38
LFA TV
1 day agoThe Resistance Is Gone | Trumpet Daily 12.26.24 7PM EST
45.3K9 -
 58:14
58:14
theDaily302
17 hours agoThe Daily 302- Tim Ballard
52.8K2 -
 13:22
13:22
Stephen Gardner
10 hours ago🔥You'll NEVER Believe what Trump wants NOW!!
102K232