Compiler From Scratch: Phase 1 - Tokenizer Generator 021: Using tokenizer in the tokenizer generator
Streamed on 2024-12-06 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
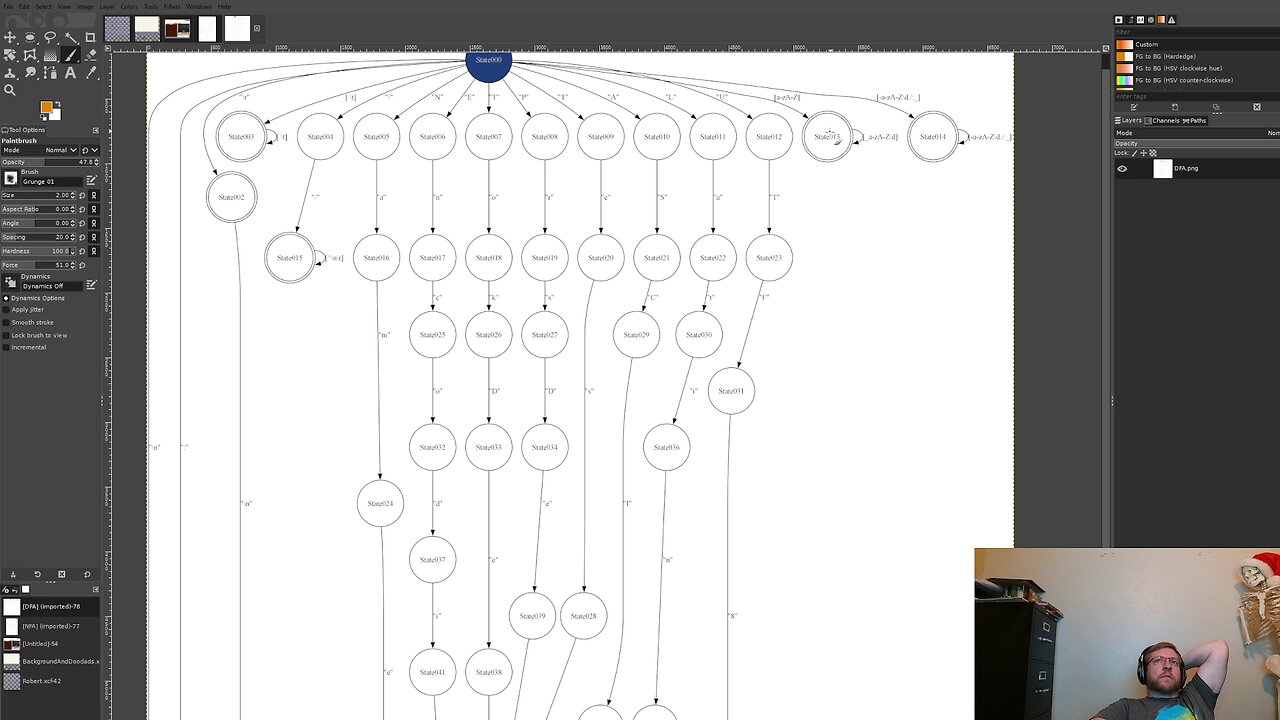
The tokenizer generator has to parse two files (so far): the project file and the tokenizer definition file. If we can generate a tokenizer, why not use that to parse those files? There's no reason not to so I started that task today. There is a bit of back and forth as you update your file parsing and the supported tokens and keeping them in sync enough to continue to build and run while making the switch.
Things were going reasonably smoothly until I ran into a bug. I thought it was a bug that I had been anticipating for quite a while, but it turned out to be something else. I anticipated it being an ordering problem, but instead it looks like our DFA isn't quite formed correctly. There are states that should be merged, like if two keywords start with the same letter. Also, there are states that should have reasonable fallbacks if they don't complete (or if they continue after the expected end) as in the case of a KEYWORD being a subset of an identifier. If the KEYWORD doesn't match exactly, it can and should still skip over into the identifier track. But that isn't happening right now.
I started looking into this bug, but didn't have time to finish it. Today's stream was a bit short and the code of interest is stuff I haven't looked at in quite a long time, so there was quite a bit of time spent trying to remember how it works and reason about what the fix should be. We'll finish debugging this next week.
-
 1:44:50
1:44:50
The Quartering
3 hours agoJ6 Hostage Release Delayed, ICE Raids Begin, Woke Pastor Vs Trump & Biden's Letter To Trump!
55.5K19 -
 LIVE
LIVE
Dr Disrespect
4 hours ago🔴LIVE - DR DISRESPECT - TRIPLE THREAT CHALLENGE - EXTREME EDITION
4,426 watching -
 6:51
6:51
Chef Donny
2 hours agoMaking Omelets With Dave Portnoy | What's For Lunch
5.87K2 -
 3:53
3:53
SLS - Street League Skateboarding
5 days agoFrom ABQ to LA - Mariah Duran’s Journey | Kona Big Wave “Beyond The Ride” Part 2
6.85K1 -
 LIVE
LIVE
Mally_Mouse
19 hours agoLet's Yap About It - LIVE!
222 watching -
 16:47
16:47
Neil McCoy-Ward
8 hours ago"We've Never Seen Anything Like It!!!" (🇬🇧 Says Private Jet Pilot)
9.54K10 -
 LIVE
LIVE
G2G Gaming Channel
6 hours agoSmite&Fortnite, Chancletazo&Helmet . Same thing if you ask me!! #RumbleGaming
150 watching -
 1:28:06
1:28:06
Russell Brand
4 hours agoInside Trump’s Inauguration: Media Frenzy, Pardons, and Power Plays – SF524
154K79 -
 1:58:47
1:58:47
The Charlie Kirk Show
4 hours agoThe Bravest Presidential Action In Decades + Trump's Spiritual Rebirth | Sen. Mullin | 1.22.2025
139K46 -
 1:41:39
1:41:39
Matt Kim
16 hours agoThe Single Best Part of Trump's Inauguration | Matt Kim #137
35.7K6