Compiler From Scratch: Phase 1 - Tokenizer Generator 015: Finishing Lazy Token Evaluation
Streamed on 2024-10-25 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
Last week we started with the Lazy evaluation build option, but didn't have time to finish it. So today we finished it.
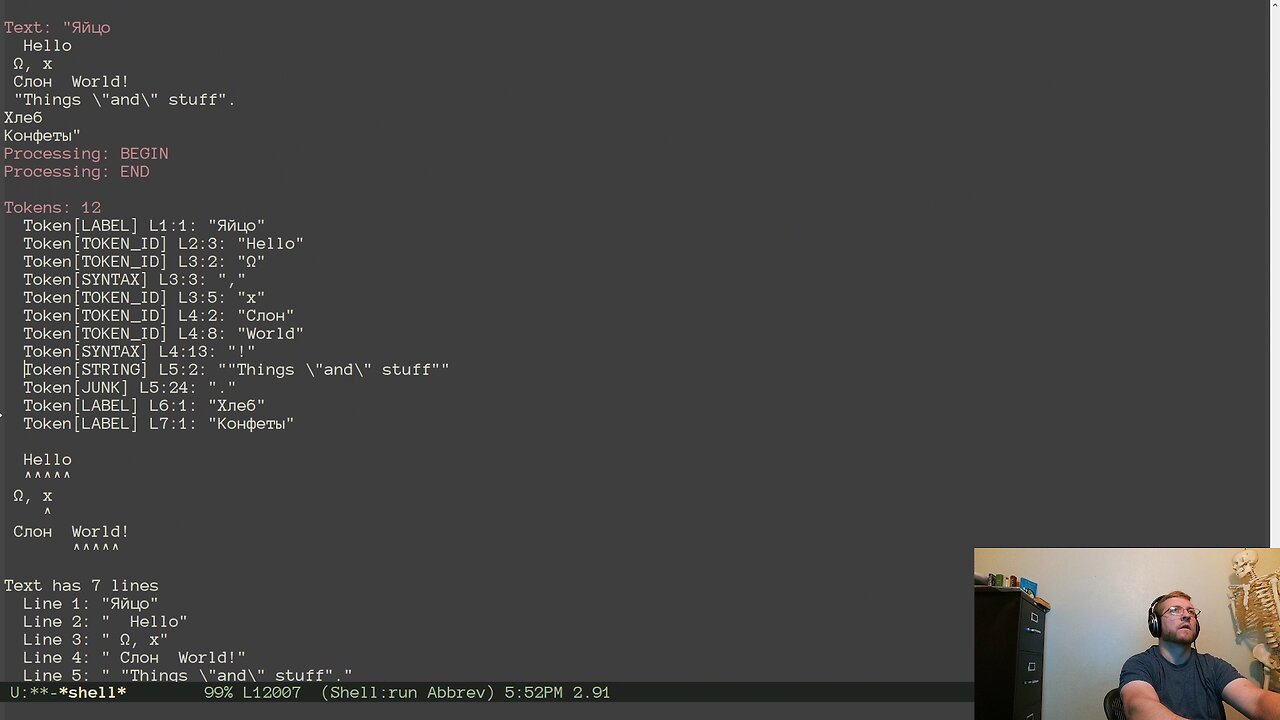
As I dug in, it became clear that I needed a way to track execution of the regex DFA states to see what was happening and when. So I started coding that in. However, that introduced a bug that caused things to crash so hard that there was no debug information. After a log to printf debugging, I narrowed it down to a single snippet of text that was being written out to a file. For some reason, copying a single word out by offset using snprintf was exploding if the source text had a "%" anywhere in it . The "%" was not in the offset/count region that was actually being copied from at all. I replaced the call to snprintf with strncpy and everything worked again. It just makes me sad how much time it took to find the reason and the solution.
Once we were back up and running there was a bit of fiddling to finish off Lazy token evaluation. There are a few differences in the way the process flows when batch processing vs lazy processing, but I found them one at a time (greatly aided by the trace log of the tokenizing process). A bit of testing with other performance flags, an update to the macros in the resulting file, and lazy processing is reasonably working for all of the build options we tested.
Next week we need to write a script to test the different combinations more automatically and efficiently. There are a lot of build configuration options now.
-
 1:04:55
1:04:55
Bare Knuckle Fighting Championship
3 days agoBKFC ITALY PRESS CONFERENCE | LIVE!
25.8K -
 10:04
10:04
Space Ice
3 hours agoThe Movie Silent Hill Is Like Resident Evil Without The Good Parts - Worst Movie Ever
14.1K3 -
 5:49
5:49
Hannah Barron
1 day agoRedneck Euro Mount
12.8K19 -
 32:34
32:34
hickok45
8 hours agoSunday Shoot-a-Round # 268
8.81K8 -
 27:33
27:33
The Finance Hub
18 hours ago $6.33 earnedBREAKING: ALINA HABBA JUST DROPPED A MASSIVE BOMBSHELL!!!
28.6K67 -
 40:23
40:23
PMG
22 hours ago $0.62 earnedHannah Faulkner and Dr. Michael Schwartz | EXPOSING BIG PHARMA
16.2K1 -
 18:55
18:55
GBGunsRumble
20 hours agoGBGuns Range Report & Channel Update 15FEB25
11.5K -
 13:31:32
13:31:32
iViperKing
21 hours agoGood Times + Good Energy Ft. Whez.. #VKGFAM #RRR
99.2K15 -
 12:24
12:24
Winston Marshall
2 days agoWOAH! Bannon just Revealed THIS About MUSK - The Tech-Right vs MAGA Right Civil War Ramps Up
225K310 -
 7:33:46
7:33:46
Phyxicx
19 hours agoRaid & Rant with the FF14 Guild on Rumble! Halo Night just wrapped up! - Go Follow all these great guys please! - 2/15/2025
151K4