Compiler From Scratch: Phase 1 - Tokenizer Generator 014: Regex code gen/testing, starting lazy eval
Streamed on 2024-10-18 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
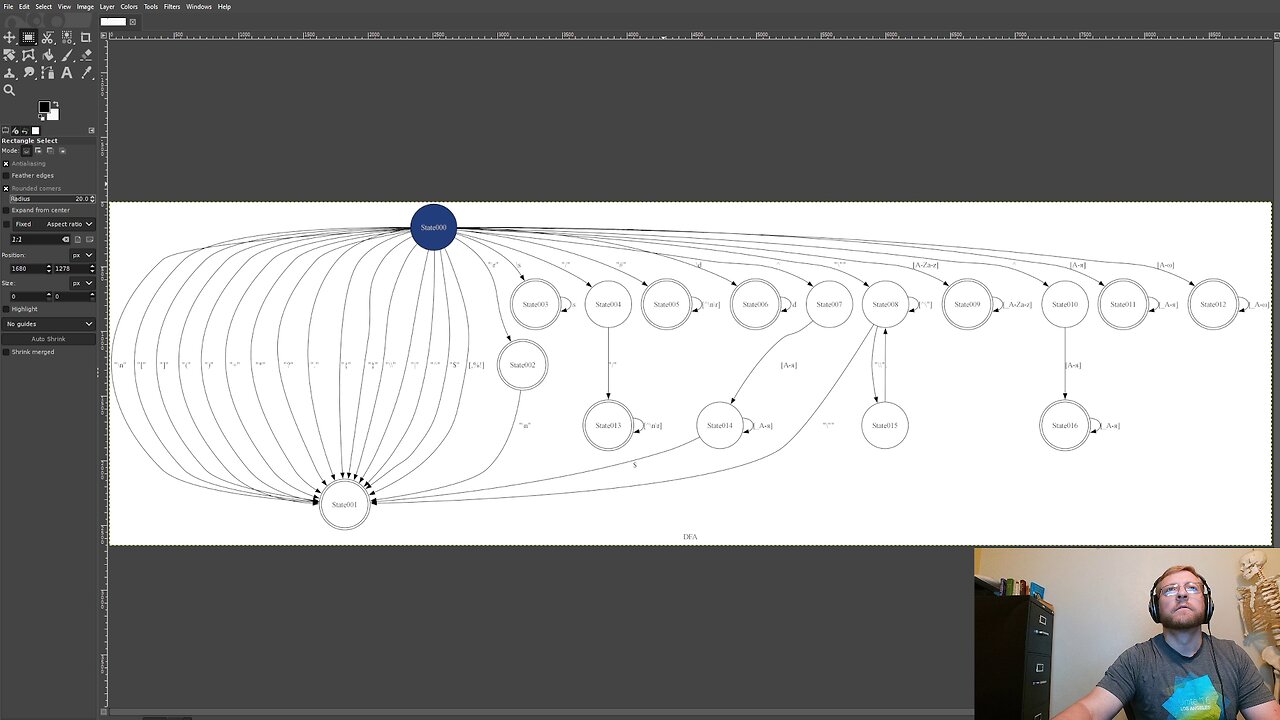
Last week we had debugged the NFA/DFA not picking up the "ANY" operator correctly and fixed it up through the DFA. I didn't like the way it printed out in the DFA table or DFA graphviz plot, so I fixed that first thing. That was followed up with a small refactor of function names left over from last week's output improvements. Just a couple of small, easy tasks to get warmed up.
After that it was time to do code generation for the ANY operator, which was easier than expected. It was basically putting "true" inside the if condition. A little debugging around the Regex for strings and it was good to go. After that I generated code for the StartOfLine and EndOfLine anchors. The main effort was two functions added to the ChrRef, then that function was called from the tokenizer. Since the anchor operators don't consume a character there was a bit of fiddling to suppress the "munch" function call in these cases. Just a bit more finagling around detecting the end of input and all was well.
I tested a couple of possible error cases with the new processing in place. One turned out to be fine, the other caused a crash as expected (unterminated string at the end of input). This was noted in the TODO for future attention.
And finally it was time to start building out the lazy tokenizer processing. There were a few opportunities to refactor/cleanup other code as we went through this exercise. The high-level methods for doing the lazy processing are put together well enough to compile, but there are still changes needed to get the whole thing working end-to-end, mostly in the helper functions. We'll pick up there next week.
-
 9:46
9:46
Mrgunsngear
8 hours ago $11.45 earnedHow To Turn Your Glock Into A PCC
65.2K11 -
 16:12
16:12
T-SPLY
17 hours agoJeff Bezos Is Now Enemy #1 For The Trump Administration
128K99 -
 12:24
12:24
Tundra Tactical
9 hours ago $6.90 earnedThe SIG Roast to ND Them All
73.1K8 -
 1:02:31
1:02:31
BonginoReport
12 hours agoDeportations Keep “Frightened” Michelle Obama Awake at Night (Ep. 37) - Nightly Scroll with Hayley
166K214 -
 1:54:29
1:54:29
Adam Does Movies
2 days ago $6.59 earnedTalking Movie News & Just Chatting About Films - LIVE!
55.4K3 -
 1:02:51
1:02:51
Anthony Rogers
1 day agoEpisode 364 - JFK FILES
30.4K2 -
 1:41:02
1:41:02
megimu32
9 hours agoON THE SUBJECT: 1 Million Views Party! Diddy Drama, Marvel Weirdness, and Total Prom Chaos
39.5K17 -
 1:18:44
1:18:44
Kim Iversen
12 hours agoMagnetic Pole Shift: Europe’s Blackout Is Just the Beginning | 90° Earth Flip Coming
122K310 -
 2:44:58
2:44:58
Laura Loomer
11 hours agoEP118: LIVE COVERAGE: Trump Celebrates 100 Days In Office At Michigan Rally
80.1K42 -
 3:40:42
3:40:42
Barry Cunningham
17 hours agoWATCH TRUMP RALLY LIVE: PRESIDENT TRUMP MARKS 100 DAYS IN OFFICE WITH A RALLY IN MICHIGAN
58.5K23