Compiler From Scratch: Phase 1 - Tokenizer Generator 012: Debugging NFA to DFA conversion
Streamed on 2024-10-04 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
Short stream.
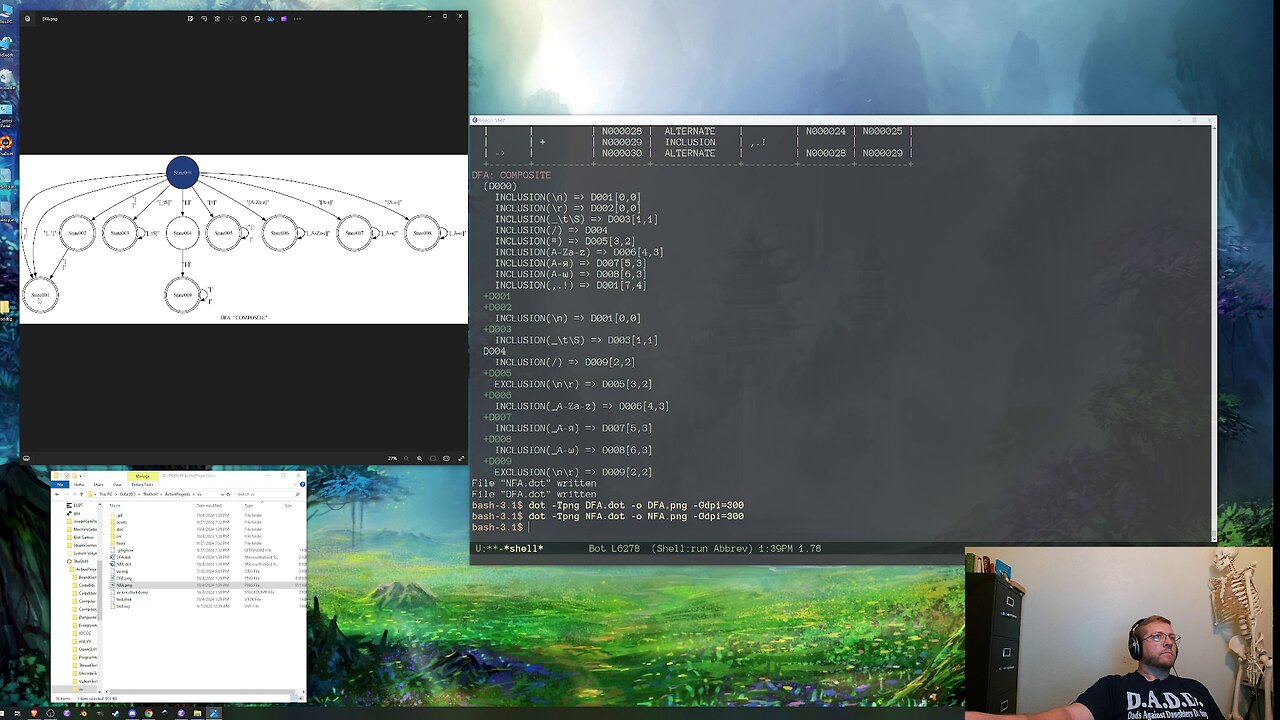
Last time we were blocked from testing the newline functionality in the tokenizer because the newline characters weren't in the DFA correctly. There was a token effort to debug the issue, but I didn't get very far at the end of the last stream. Which brings us to today where I got serious about the issue. With lots of debugging print statements I found the issue where in the NFA to DFA conversion process. The problem was that when a state was being added to the closure it was already marked as "visited" and its children were then not being processed on the next time through the loop. A quick test and clearing that flag fixed the main issue.
While the DFA was looking better, the pattern for the newline character didn't look right. I changed the newline pattern from "([\n\r]|(\r\n))" to "(\n|(\r\n?))" and was much happier about the results. Those changes let us finally test the newline function in the tokenizer. The tokens are getting the right line numbers now. I tried to trim the newline characters off the end of the line as tracked by TxtBuf, but didn't have time to finish that off.
I also did a quick test of the string regex pattern, but didn't have time to dig in, although I have some ideas to check. So I left off with a couple of loose ends due to the shortness of the stream that we'll pick up next week.
-
 47:39
47:39
Michael Franzese
2 hours agoJewelry King Trax NYC EXPOSES How the Powerful Steal from You
23.8K2 -
 40:43
40:43
Kimberly Guilfoyle
5 hours agoDems Double Down on Delusion-Why? Live with Tony Kinnett & Bo French | Ep.202
48.1K16 -
 1:28:42
1:28:42
Redacted News
4 hours agoBREAKING! SOMETHING BIG IS HAPPENING IN EUROPE ALL OUT WAR IS COMING AGAINST RUSSIA, TRUMP FURIOUS
95.4K208 -
 47:50
47:50
Candace Show Podcast
4 hours agoBREAKING: Judge Makes Statement Regarding Taylor Swift's Text Messages. | Candace Ep 155
77.1K74 -
 LIVE
LIVE
CatfishedOnline
2 hours agoGoing Live With Robert - Weekly Recap
123 watching -
 LIVE
LIVE
LFA TV
1 day agoEurope’s Sudden Turn Against America | TRUMPET DAILY 3.6.25 7PM
484 watching -
 4:21
4:21
Tundra Tactical
2 hours agoPam Bondi MUST Enforce Due Process NOW!
9.43K -
 56:42
56:42
VSiNLive
3 hours agoFollow the Money with Mitch Moss & Pauly Howard | Hour 1
31.6K1 -
 1:05:32
1:05:32
In The Litter Box w/ Jewels & Catturd
1 day agoShalom Hamas | In the Litter Box w/ Jewels & Catturd – Ep. 756 – 3/6/2025
88.9K36 -
 1:23:00
1:23:00
Sean Unpaved
5 hours ago $2.81 earnedNFL Free Agency
44.7K3