Compiler From Scratch: Phase 1 - Tokenizer Generator 009: Generating DFA State code
Streamed on 2024-09-13 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
I have to confess to cheating ... I did some work on the compiler off-stream. I created an asset pipeline for managing Code Snippets ... large chunks of text that are the same no matter what. These Code Snippets can be divided into chunks with a line of "...", so I can write a chunk, then emit custom code, and move on to the next chunk. The other thing was I refactored TxtBuf and ChrRef to remove the circular dependency that would necessarily exist if I use ChrRef in a TxtBuf::Iterator. And now I have a TxtBuff::Iterator. But that was all the cheating, I swear! Everything else we do on-stream.
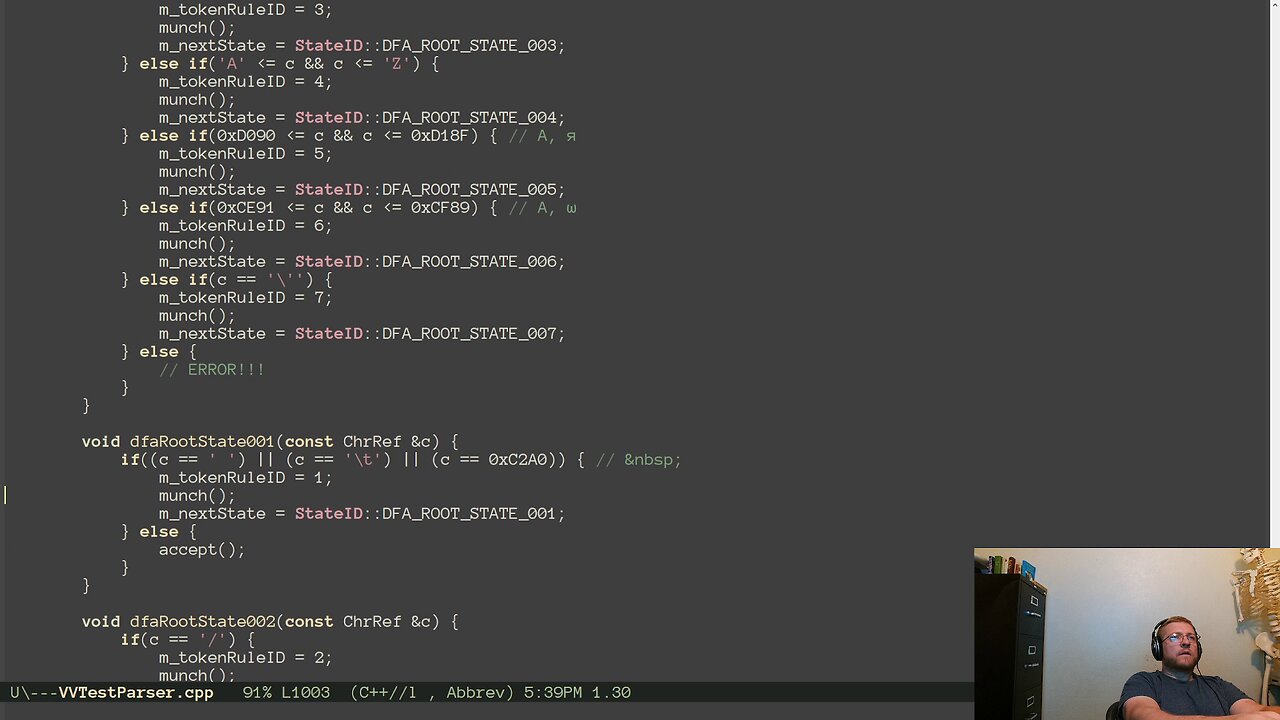
Today was starting to emit DFAStates into our Tokenizer. Each DFAState has a list of Transitions and each Transition contains a list of conditions to check, and where the next DFAState is if those conditions are met. All the code emitted today was into simple methods, one per DFAState.
But a lot of the complexity we will face will come in the form of the PerformanceSwitches I am putting in. Whenever I come to a decision that I think will impact performance I am emitting code for each of those decisions, wrapped in a #ifdef/#endif so we can change some defines in our build and test the alternatives. There is some overlap between some of the options I've thought up, so we are going to be emitting way more code than we will end up with. As we go we will confirm correctness of each PerformanceSwitch, but we won't profile until things are working end-to-end and we have a large body of text to test against ... maybe JSON? So, if this stage of development seems a little slow, remember, I am generating 96 (currently) permutations of the way this code could be written.
-
 41:53
41:53
Rethinking the Dollar
1 hour agoHype or Hope? Will THE 50-YEAR FORT KNOX GOLD SCANDAL BE EXPOSED?
5.83K1 -
 1:32:36
1:32:36
Game On!
15 hours ago $8.63 earnedPresident Trump TAKES OVER the Daytona 500!
44.4K12 -
 21:35
21:35
DeVory Darkins
3 days ago $25.28 earnedMitch McConnell TORCHED as Secretary of HHS is sworn in
134K188 -
 1:20:04
1:20:04
Tim Pool
4 days agoGame of Money
183K12 -
 4:48
4:48
Cooking with Gruel
16 hours agoThe Perfect Bacon
24.9K3 -
 11:49
11:49
Reforge Gaming
4 hours agoXbox - Next Game on PlayStation?
17.6K4 -
 27:46
27:46
ArturRehi
1 day agoSurprise Counter-Attack in Kursk Advanced 3 Miles | French Jets Arrive | Ukraine Update
27.7K7 -
 11:51
11:51
Alabama Arsenal
15 hours ago $4.63 earnedThe Silent Sledgehammer | GQ Armory 8.6BLK Paladin
71.4K1 -
 2:21:11
2:21:11
Nerdrotic
19 hours ago $39.67 earnedDown the Rabbit Hole with Kurt Metzger | Forbidden Frontier #090
196K41 -
 2:41:13
2:41:13
vivafrei
1 day agoEp. 251: Bogus Social Security Payments? DOGE Lawsduit W's! Maddow Defamation! & MORE! Viva & Barnes
304K315