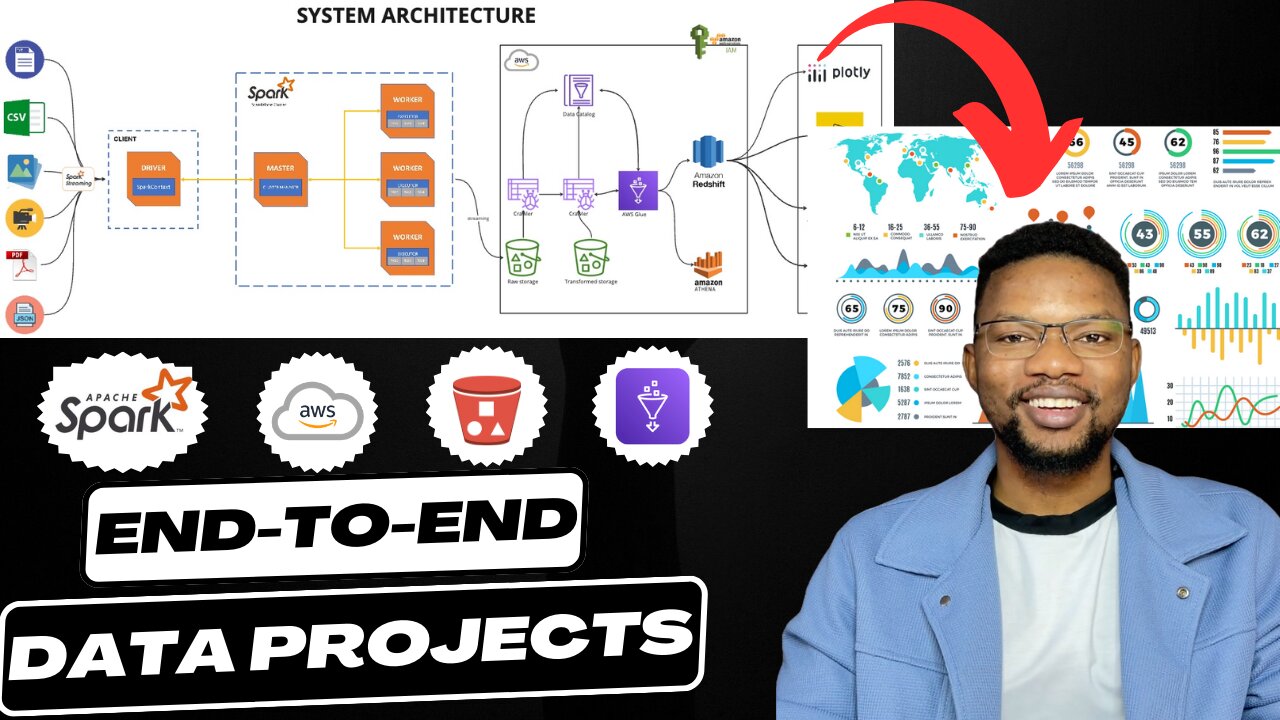
Realtime Streaming with Unstructured Data Engineering | Get Hired as an Experienced Data Engineer
In this video you will be building a realtime streaming pipeline for unstructured data with different data types (TEXT, IMAGE, VIDEO, CSV, JSON, PDF) with over 600+ different datasets.
MORE DATA ENGINEERING VIDEOS AVAILABLE on datamasterylab.com
Like this video?
- Buy me a coffee: https://www.buymeacoffee.com/yusuf.ganiyu
- Support the channel: https://www.youtube.com/@codewithyu/join
Timestamps:
0:00 Introduction
1:50 System Architecture Overview
4:08 System Architecture Design
13:22 Setting up Spark Streaming for Unstructured Data
21:46 Handling multiple unstructured data types
24:31 Creating data schema
30:35 Creating custom user define functions for data extraction
51:14 Parsing and extracting text data
1:40:30 Structuring the results into a dataframe
1:46:15 Reading JSON structured files into the streams
1:49:47 Joining Structured and Unstructured Data Streams
1:52:50 Writing Data to AWS S3 Bucket
2:04:20 Creating AWS Glue Crawler for the data
2:08:25 Verifying the crawler results on Athena
2:11:36 Deploying Spark Streams to Spark Clusters
2:26:31 Verification of Results
2:29:40 Outro
👦🏻 My Linkedin: https://www.linkedin.com/in/yusuf-ganiyu-b90140107/
🚀 X(Twitter): https://x.com/YusufOGaniyu
📝 Medium: https://medium.com/@yusuf.ganiyu
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✅ Source Code and Datasets: https://www.buymeacoffee.com/yusuf.ganiyu/source-code-real-time-streaming-pipelines-unstructured-data
✅ Docker Compose Documentation: https://docs.docker.com/compose/
✅ Apache Spark Official Site: https://spark.apache.org/
✅ Confluent Docs: https://docs.confluent.io/home/overview.html
✅ S3 Documentation: https://docs.aws.amazon.com/s3/
✅ AWS IAM Documentation: https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html
✨ Tags ✨
Data Engineering, Apache Spark, Unstructured Data, Docker, Docker Compose, ETL Pipeline, Data Pipeline, Big Data, Streaming Data, Real-time Analytics, Kafka Connect, Spark Master, Spark Worker, Schema Registry, Control Center, Data Streaming
✨ Hashtags ✨
#DataEngineering #ApacheSpark #unstructureddata #Docker #ETLPipeline #DataPipeline #StreamingData #RealTimeAnalytics
-
 LIVE
LIVE
GamerGril
48 minutes agoIM THE GREASTEST OF ALL TIME AT.... CHAOS | DAYS GONE
809 watching -
 LIVE
LIVE
Due Dissidence
1 day agoTHE PEOPLE VS NATURE by Kevin Augustine - plus a talkback w/ Jimmy Dore
1,169 watching -
 LIVE
LIVE
Rotella Games
6 hours agoMake the Hood Great Again | Day 3 | GTA San Andreas
790 watching -
 LIVE
LIVE
PudgeTV
6 hours ago🟡 Practical Pudge Ep 48 with "Willie Faulk" | Catching Up With Old Friends
1,329 watching -
 18:32
18:32
Forrest Galante
19 hours ago5 Extinct Animals That I Believe Could Still Be Alive...
125K30 -
 DVR
DVR
Major League Fishing
3 days agoLIVE! - General Tire Team Series: Summit Cup - Day 1
90.1K2 -
 7:05:23
7:05:23
Hevel Gaming
22 hours ago $65.97 earnedNCAAF Tennessee at Georgia While with Heroes of Might and Magic III & Helldivers 2
211K22 -
 6:34:08
6:34:08
MissesMaam
20 hours agoI'm Addicted | Sons of the Forest 💚✨
159K30 -
 11:22:12
11:22:12
a12cat34dog
22 hours agoALMOST HAVE ALL GUNS DIAMOND :: Call of Duty: Black Ops 6 :: SO MANY ZOMBIES CAMOS {18+}
96K4 -
 3:32:31
3:32:31
United Fight League
23 hours agoUFC 309 Watch Party w/ Rampage Jackson, Maycee Barber, Demi Bagby, and Harrison Rogers
215K40