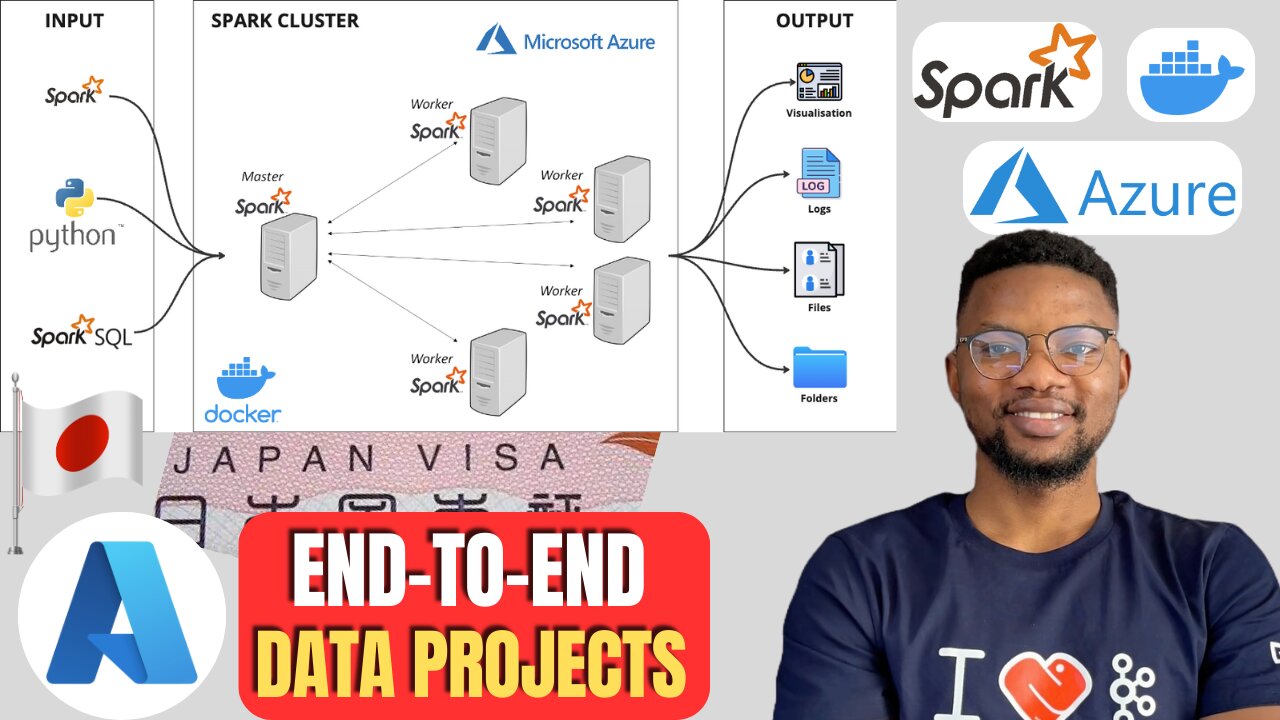
Japan Visa Analysis: Azure Data End to End Data Engineering
In this tutorial, you will set up the Spark master-worker architecture in a Docker container on Azure. 🚀 We'll then perform end-to-end data processing and visualization of visa numbers in Japan using PySpark and Plotly. 📈 Learn how to clean, transform, and visualize your data in an interactive manner, and gain insights into visa trends in Japan. 🇯🇵
What You Will Learn:
🛠 Setting up Spark master-worker architecture in Docker on Azure.
📖 Reading and cleaning data using PySpark.
🔄 Data transformation techniques with PySpark.
🎨 Visualizing data trends using Plotly Express.
💾 Exporting your visualizations and cleaned data.
Timestamps:
0:00 Introduction
1:15 Setting up the system architecture
05:00 Setting up cloud clusters
17:05 Coding
55:00 Results
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
Resources and Links:
Github Code: https://github.com/airscholar/Japan-visa-data-engineering.git
Dataset: https://www.kaggle.com/datasets/yutodennou/visa-issuance-by-nationality-and-region-in-japan
Docker Documentation: https://docs.docker.com/engine/install/ubuntu/
Spark Official Documentation: https://spark.apache.org/docs/latest/api/python/index.html
Pyspark Documentation: https://pypi.org/project/pyspark/
Python Levenshtein Documentation: https://pypi.org/project/python-Levenshtein/
Tags:
PySpark, Plotly, Data Visualization, Data Cleaning, Docker, Azure, Spark Architecture, Data Analysis
Hashtags:
#PySpark #Plotly #DataVisualization #Azure #Docker #SparkTutorial #DataAnalysis
-
 LIVE
LIVE
Tucker Carlson
40 minutes agoRay Dalio: America’s Hidden Civil War, and the Race to Beat China in Tech, Economics, and Academia
4,049 watching -
 LIVE
LIVE
Candace Show Podcast
1 hour agoEXCLUSIVE: Taylor Swift Will Be Deposed. | Candace Ep 150
6,309 watching -
 LIVE
LIVE
Dr Disrespect
5 hours ago🔴LIVE - DR DISRESPECT - WARZONE - IMPOSSIBLE TRIPLE THREAT CHALLENGE
3,550 watching -
 1:04:05
1:04:05
In The Litter Box w/ Jewels & Catturd
21 hours agoYOU'RE FIRED! | In the Litter Box w/ Jewels & Catturd – Ep. 747 – 2/21/2025
26K17 -
 LIVE
LIVE
Revenge of the Cis
1 hour agoLocals Movie Riff: Soul Plane
339 watching -
 40:04
40:04
SLS - Street League Skateboarding
1 month agoThese 2 Women Dominated 2024! Best of Rayssa Leal & Chloe Covell 🏆
29.1K2 -
 1:48:12
1:48:12
The Quartering
5 hours agoElon Musk Waves a Chainsaw at CPAC, JD Vance SLAMS Illegal Immigration, and more
89.1K20 -
 45:20
45:20
Rethinking the Dollar
2 hours agoGolden Opportunity: Trump's Noise Has Been Great For Gold But....
12.7K4 -
 1:02:04
1:02:04
Ben Shapiro
4 hours agoEp. 2143 - The True Faces Of Evil
78.3K85 -
 1:26:19
1:26:19
Game On!
4 hours ago $1.65 earnedSports Betting Weekend Preview with Crick's Corner!
29.9K1