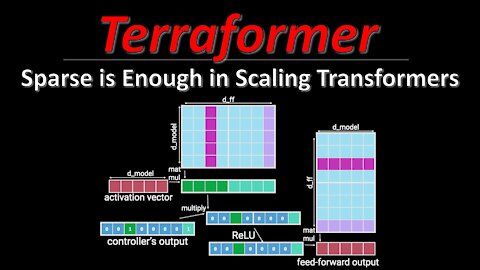
2 years agoSparse is Enough in Scaling Transformers (aka Terraformer) | ML Research Paper Explainedykilcher
3 years agoFastformer: Additive Attention Can Be All You Need (Machine Learning Research Paper Explained)ykilcher
3 years agoDeBERTa: Decoding-enhanced BERT with Disentangled Attention (Machine Learning Paper Explained)ykilcher
1 year agoGoogle just released 10 FREE courses to master Generative AI. ( 4 New Courses🔥)raheelkhan2000
3 years agoPretrained Transformers as Universal Computation Engines (Machine Learning Research Paper Explained)ykilcher
3 years agoDecision Transformer: Reinforcement Learning via Sequence Modeling (Research Paper Explained)ykilcher
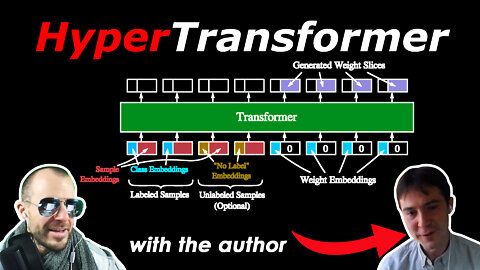
2 years agoHyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning (w/ Author)ykilcher
1 year agoUnderstanding Query, Key and Value Vectors in Transformer NetworksExploring the future of technology
3 years agoALiBi - Train Short, Test Long: Attention with linear biases enables input length extrapolationykilcher
1 year agoAWS exec downplays existential threat of AI, calls it a 'mathematical parlor trick' - VentureBe...Best Product Reviews
1 year agoWhy Elon Musk Called ChatGPT "SCARY GOOD DANGEROUSLY STRONG AI" | Tutorial 4YouEasy to Follow Tutorials
1 year ago🐐 OpenAI Tutorial - Learn Text Completion with OpenAI, ChatGPT, Next.Js, React & TailwindCSSthecodinggoat
1 year agoA Comprehensive Guide to the GPT: GENERATIVE Pre-TRAINED TRANSFORMER modelKnowledgeInPieces
1 year agoFrom Thought to Text: AI Converts Silent Speech into Written Words - Neuroscience NewsBest Product Reviews